若您沒有網路爬文的經驗,可以先參考Python網路爬文
接下來您可以在網頁上按右鍵,選擇檢視網頁原始碼,如下圖。
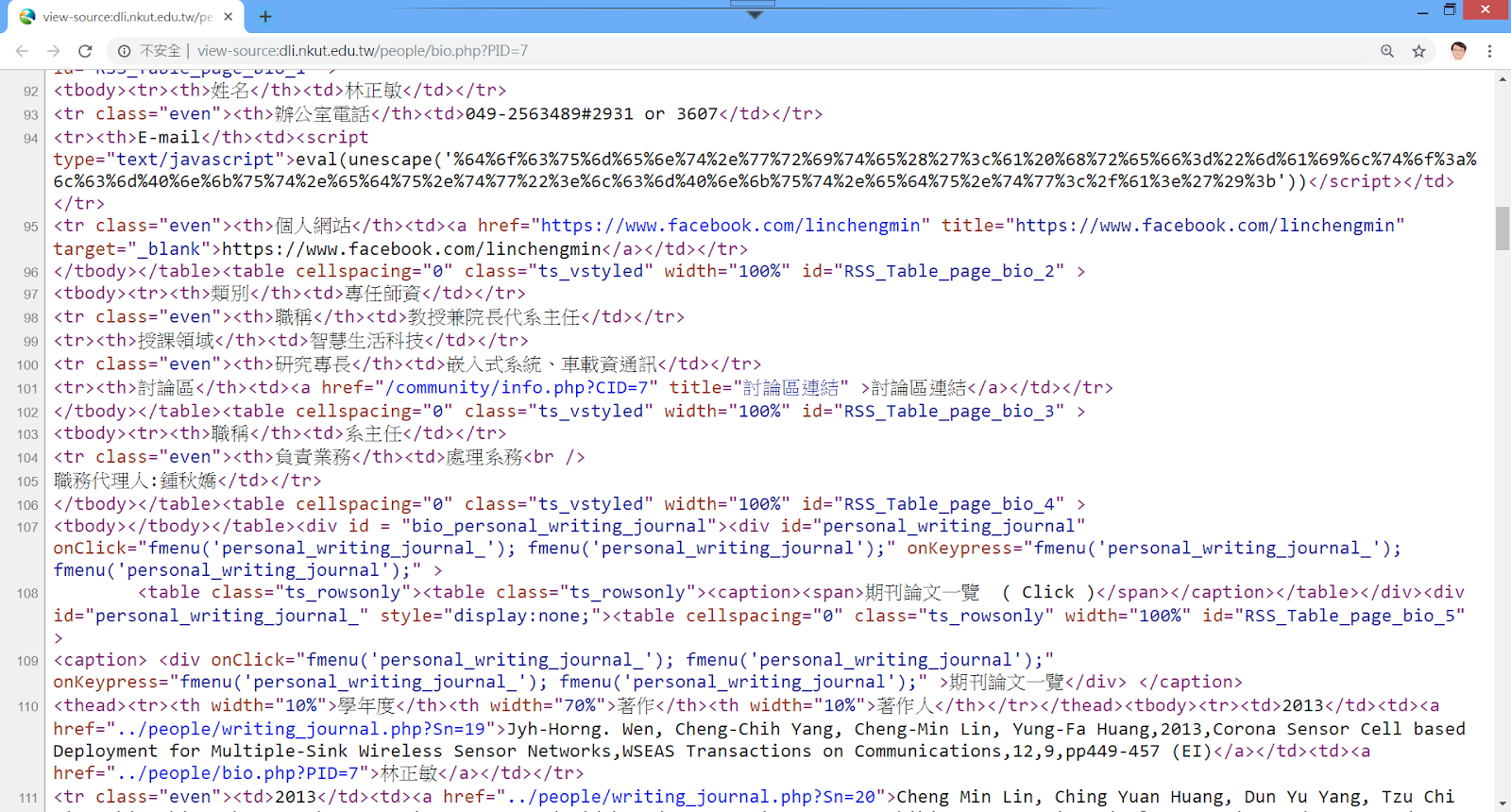
從上圖中可以發現,在期刊部份是使用表格
程式如下:
import requests
from bs4 import BeautifulSoup
url = "http://dli.nkut.edu.tw/people/bio.php?PID=7"
re = requests.get(url)
re.encoding='utf8'
state = 0
sub_state = 0
soup = BeautifulSoup(re.text, 'html.parser')
print(soup.title.string)
for row in soup.find_all('table'):
if state == 0:
print(soup.find('td').string)
elif state == 1:
substate = 0
for column in row.find_all('tr'):
if substate == 1:
print(column.find('td').string)
substate+=1
elif state == 6:
print(row.find('div').string)
substate = 0
for column in row.find_all('tr'):
if substate > 0:
print(substate)
for paper in column.find_all('td'):
print(paper.string)
substate+=1
elif state == 9:
print(row.find('div').string)
substate = 0
for column in row.find_all('tr'):
if substate > 0:
print(substate)
for paper in column.find_all('td'):
print(paper.string)
substate+=1
elif state == 12:
print(row.find('div').string)
substate = 0
for column in row.find_all('tr'):
if substate > 0:
print(substate)
for paper in column.find_all('td'):
print(paper.string)
substate+=1
state+=1
